5.1.- Introducción
Desde tiempos inmemoriales, los
humanos han almacenado los datos en algún tipo de soporte (piedra,
papel, madera, etc.) a fin de que quedara constancia. Así mismo
estos datos han de ser interpretados para que se conviertan en
información útil, interpretación que supone un fenómeno de
agrupación y clasificación.
Actualmente las bases de datos son el método preferido para el
almacenamiento estructurado de datos. Desde las grandes
aplicaciones multiusuario, hasta los teléfonos móviles y las
agendas electrónicas utilizan tecnología de bases de datos para
asegurar la integridad de los datos y facilitar la labor tanto de
usuarios como de los programadores que las desarrollaron.
Desde la realización del primer modelo de datos, pasando por la
administración del sistema gestor, hasta llegar al desarrollo de la
aplicación, los conceptos y la tecnología asociados son muchos y
muy heterogéneos. Sin embargo, es imprescindible conocer los
aspectos clave de cada uno de estos temas para tener éxito en
cualquier proyecto que implique trabajar con bases de datos.
En los años 40 del siglo pasado, los sistemas de archivos generados
a través de los primeros lenguajes de programación como
Cobol y
Fortran, permitieron almacenar los datos a través de archivos
sin formato alguno (texto plano, como por ejemplo cuando se guarda
un texto en el editor de textos sin ningún formato) con las únicas
funciones de lectura y escritura.
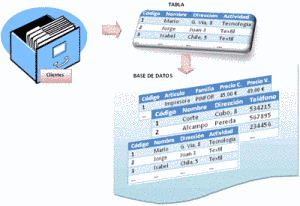
Posteriormente surgió el denominado sistema de
ficheros que es un conjunto de programas que prestan
servicio a los usuarios finales. Cada programa define y maneja sus
propios datos. Los sistemas de ficheros surgieron al tratar de
informatizar el manejo de los archivadores manuales con objeto de
proporcionar un acceso más eficiente a los datos. En lugar de
establecer un sistema centralizado en donde almacenar todos los
datos de la organización o empresa, se escogió un modelo
descentralizado en el que cada división o departamento almacena y
gestiona sus propios datos.
Los sistemas de ficheros presentan una serie de inconvenientes:
- Separación y aislamiento de los datos. Cuando los datos se separan en diferentes ficheros, es más complicado acceder a ellos, ya que el programador de aplicaciones debe sincronizar el procesamiento de los distintos ficheros implicados para asegurar que se extraen los datos correctos.
- Duplicación de datos. La redundancia de datos existente en los sistemas de ficheros hace que se desperdicie espacio de almacenamiento y lo que es más importante, puede llevar a que se pierda la consistencia de los datos. Se produce una inconsistencia cuando copias de los mismos datos no coinciden.
- Dependencia de datos. Ya que la estructura física de los datos (la definición de los ficheros y de los registros) se encuentra codificada en los programas de aplicación, cualquier cambio en dicha estructura es difícil de realizar. El programador debe identificar todos los programas afectados por este cambio, modificarlos y volverlos a probar, lo que cuesta mucho tiempo y está sujeto a que se produzcan errores. A este problema, tan característico de los sistemas de ficheros, se le denomina también falta de independencia de datos lógica-física.
- Formatos de ficheros no compatibles. Ya que la estructura de los ficheros se define en los programas de aplicación, es completamente dependiente del lenguaje de programación. La incompatibilidad entre ficheros generados por distintos lenguajes hace que los ficheros sean difíciles de procesar de modo conjunto.
- Consultas fijas y proliferación de programas de aplicación. Desde el punto de vista de los usuarios finales, los sistemas de ficheros fueron un gran avance comparados a los sistemas manuales. Como consecuencia de esto, creció la necesidad de realizar distintos tipos de consultas de datos, sin embargo, los sistemas de ficheros son muy dependientes del programador de aplicaciones: cualquier consulta o informe que se quiera realizar debe ser programado por él. En algunas organizaciones se conformaron con fijar el tipo de consultas e informes, siendo imposible realizar otro tipo de consultas que no se hubieran tenido en cuenta a la hora de escribir los programas de aplicación.
Los inconvenientes de los sistemas de ficheros se pueden atribuir a dos factores:
- No hay control sobre el acceso y la manipulación de los datos más allá de lo impuesto por los programas de aplicación.Definición y características de un Sistema Gestor de Bases de Datos.
El objetivo básico de cualquier
base de datos es el almacenamiento de símbolos, números y letras
carentes de un significado en sí, que mediante un tratamiento
adecuado se convierten en información útil. Un ejemplo podría ser
el siguiente dato: 20131224, con el tratamiento correcto podría
convertirse en la siguiente información: "Fecha de nacimiento: 24
de diciembre del año 2013".
Según van evolucionando en el tiempo, las necesidades de
almacenamiento de datos van creciendo y con ellas las necesidades
de transformar los mismos datos en información de muy diversa
naturaleza. Esta información es utilizada como herramientas de
trabajo y soporte para la toma de decisiones por un gran colectivo
de profesionales que consideran dicha información como base de su
actividad. Por este motivo el trabajo del diseñador de bases de
datos es cada vez más delicado, un error en el diseño o en la
interpretación de datos puede dar lugar a información incorrecta y
conducir al usuario a la toma de decisiones equivocadas. Se hace
necesario la creación de un sistema que ayude al diseñador a crear
estructuras correctas y fiables, minimizando los tiempos de diseño
y explotando todos los datos, así nació la metodología de diseño de
bases de datos.
Se puede definir una base de datos, como un
fichero en el cual se almacena información de cualquier tipo. En
dicho fichero la información se guarda en campos o delimitadores,
por ejemplo, podemos almacenar el nombre y apellidos de las
personas de modo separado, de ésta forma es posible obtener del
fichero todos los nombres o todos los apellidos, tanto de forma
separada como conjunta. Normalmente el número de campos que se
tienen en una base varía según las necesidades en cuanto a gestión
de datos, de forma que después se pueda explotar la información de
forma ordenada y separada, aunque el resto de la información sigue
almacenada y guardada en la base de datos.
Una base de datos, no es sólo el fichero en donde están datos, sino
que en dicho archivo se encuentra la estructura de los datos, así
que para saber qué longitud tiene cada campo, hay que conocer como
se llama el campo y qué longitud en caracteres tiene, así como el
tipo de datos en dicho campo, porque puede contener desde letras a
números o incluso otros datos más complejos, dependiendo de la
estructura de la base y del sistema gestor.
En realidad aparte de los datos que son almacenados en el archivo,
también otra serie de datos, en los que se informa del tipo de
campo, los campos y la longitud de cada campo, es lo que se llama
gestor de datos, que permite saber que cada registro (un registro
es una suma de campos, por ejemplo a Marisol Collazos, Marisol lo
guardamos en el campo Nombre y Collazos en el campo Apellidos, cada
registro es cada persona que almacenamos en la base, osea una
persona es un registro y cada registro está constituido por los
campos Nombre y Apellido.
Un Sistema Gestor de Bases de Datos (SGBD) es una serie de recursos
para manejar grandes volúmenes de información, sin embargo no todos
los sistemas que manejan información son bases de datos.
Para trabajar de un modo más efectivo, en 1964, se diseñaron los
primeros Gestores de Base de Datos (SGDB o DBMS),
por medio de los que se pretendía dar un cambio total a los
sistemas de archivos. Con los DBMS se creó el concepto de
administración de datos, por medio de actividades integradas que
permiten verlos físicamente en un almacenamiento único pero
lógicamente se manipulan a través de esquemas compuestos por
estructuras donde se establecen vínculos de integridad, métodos de
acceso y organización física sobre los datos, permitiendo así
obtener valores agregados de utilización tales como: manejo de
usuarios, seguridad, atomicidad e independencia física y lógica de
los datos, entre otros.
Los sistemas de bases de datos tienen su origen en el proyecto
estadounidense Apolo de mandar al hombre a la luna, gran cantidad
de información que requería el proyecto. La primera empresa
encargada del proyecto, NAA (North American Aviation),
desarrolló un software denominado GUAM (General Update Access
Method) que estaba basado en el concepto de que varias piezas
pequeñas se unen para formar una pieza más grande, y así
sucesivamente hasta que el producto final está ensamblado.
El primer sistema gestor de bases de datos comercial, IDS
(Integrated Data Store) de General Electric y Bull, se
diseñó bajo el concepto de modelo de datos en red (Bachgman, 1965).
Posteriormente se desarrolló el IMS (Information Management
System) de IBM, sobre el concepto del modelo de datos
jerárquico. A estos sistemas se accedía normalmente mediante
lenguajes de programación como COBOL usando interfaces de bajo
nivel, lo cual implicaba que las tareas de creación de aplicaciones
y mantenimiento de los datos fueran controlables, aunque bastante
complejas.
Durante los años ochenta del siglo pasado aparecen y se difunden
rápidamente los ordenadores personales. También surge software para
estos equipos monousuario (por ejemplo, dBase y sus derivados,
Access), con los cuales es fácil crear y utilizar conjuntos de
datos, y que se denominan personal data bases. El hecho de
denominar SGBD a estos primeros sistemas para PC es un poco
forzado, ya que no aceptaban estructuras complejas ni
interrelaciones, ni podían ser utilizados en una red que sirviese
simultáneamente a muchos usuarios de diferentes tipos. Sin embargo,
algunos, con el tiempo, se han ido convirtiendo en auténticos
SGBD.
Actualmente, los SGBD relacionales están en plena transformación
para adaptarse a tres tecnologías de éxito reciente, fuertemente
relacionadas: la multimedia, la de orientación a objetos (OO) e
internet y la web.
Sin embargo, algunas aplicaciones no tienen suficiente con la
incorporación de tipos especializados en multimedia. Necesitan
tipos complejos que el desarrollador pueda definir a medida de la
aplicación. En definitiva, se necesitan tipos abstractos de datos
(TAD). Los SGBD más recientes ya incorporan esta posibilidad, y
abren un amplio mercado de TAD predefinidos o librerías de
clases.
Esto conduce a la orientación a objetos (OO). El éxito de la OO al
final de los años ochenta, en el desarrollo de software básico, en
las aplicaciones de ingeniería industrial y en la construcción de
interfaces gráficas con los usuarios, ha hecho que durante la
década de los noventa se extendiese en prácticamente todos los
campos de la informática.
La amplia difusión de la web ha dado lugar a que los SGBD
incorporen recursos para ser servidores de páginas web, como por
ejemplo la inclusión de SQL en páginas web en lenguaje HTML, SQL
incorporado en Java, etc.
Durante estos últimos años se ha empezado a extender un tipo de
aplicación de las BD denominado Data Warehouse, o almacén
de datos, que también produce algunos cambios en los SGBD
relacionales del mercado.
Un sistema de bases de datos debe responder a las siguientes
características:
- Independencia de los Datos. Es decir, que los datos nunca dependen del programa y por tanto cualquier aplicación pueda hacer uso de éllos.
- Reducción de la Redundancia. Redundancia es la existencia de duplicación de los datos, al reducir ésta al máximo conseguimos un mejor aprovechamiento del espacio y además evitamos que existan inconsistencias entre los datos. Las inconsistencias se dan cuando nos encontramos con datos contradictorios.
- Seguridad. Un SGBD debe permitir que tengamos un control sobre la seguridad de los datos, frente a usuarios malintencionados que intenten leer información no permitida; frente a ataques que deseen manipular o destruir la información; o simplemente ante las torpezas de algún usuario autorizado.
- Integridad. Se trata de adoptar las medidas necesarias para garantizar la validez de los datos almacenados. Se trata de proteger los datos ante fallos de hardware, datos introducidos por usuarios descuidados, o cualquier otra circunstancia capaz de corromper la información almacenada. Los SGBD proveen mecanismos para garantizar la recuperación de la base de datos hasta un estado consistente conocido en forma automática.
- Respaldo. Los SGBD deben proporcionar una forma eficiente de realizar copias de seguridad de la información almacenada en ellos, y de restaurar a partir de estas copias los datos que se hayan podido perder. - Control de la concurrencia. En la mayoría de entornos (excepto quizás el personal), lo más habitual es que sean muchas las personas que acceden a una base de datos, bien para recuperar información, bien para almacenarla. Y es también frecuente que dichos accesos se realicen de forma simultánea. Así pues, un SGBD debe controlar este acceso concurrente a la información, que podría derivar en inconsistencias.
- Manejo de transacciones. Una transacción es un programa que se ejecuta como una sola operación. Esto quiere decir que el estado luego de una ejecución en la que se produce un fallo es el mismo que se obtendría si el programa no se hubiera ejecutado. Los SGBD proveen mecanismos para programar las modificaciones de los datos de una forma mucho más simple que si no se dispusiera de ellos.
- Tiempo de respuesta. Lógicamente, es deseable minimizar el tiempo que el SGBD tarda en darnos la información solicitada y en almacenar los cambios realizados.